


24 Ott Musica e fisica: la digitalizzazione del segnale acustico
Chi l’ha detto che la fisica, l’elettronica e la programmazione non abbiano niente a che fare con la musica?
Un suono, infatti, è semplicemente la propagazione di un’onda nell’aria che fa vibrare il timpano del nostro orecchio generando un impulso nervoso diretto al cervello.
Esattamente come le onde radio o quelle elettromagnetiche, anche le onde sonore possono essere catturate, analizzate e modulate a nostro piacimento.
Ed è proprio quello che fa una scheda audio: raccoglie un segnale sonoro esterno (analogico) e lo “digitalizza”, ovvero lo traduce in un linguaggio comprensibile ed elaborabile dal nostro PC.
Questo processo di digitalizzazione si divide in due parti fondamentali:
- campionamento: vengono prelevati dati rappresentativi del segnale ad intervalli regolari di tempo;
- quantizzazione: approssimazione del valore campionato col numero più vicino rappresentabile dal computer.
Il campionamento
Con il termine “campionamento” si intende letteralmente estrarre dei campioni di un segnale variabile ad intervalli regolari di tempo.
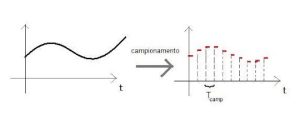
Figura 1 – Campionamento di un segnale analogico
Come si può vedere dalle immagini sotto, dato un segnale analogico di partenza, minore è la distanza tra i punti (ovvero maggiore è la frequenza di campionamento), più simile è la curva campionata a quella originale.
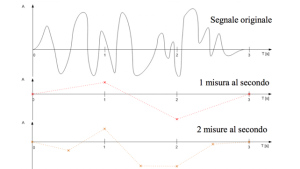
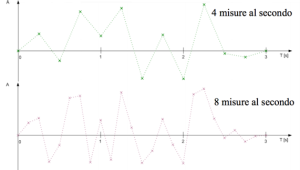
Figura 2 – Campionamenti a diverse frequenze
A questo punto verrebbe spontaneo chiedersi: ma esiste una frequenza di campionamento ideale?
Per nostra sfortuna no, non esiste. Questo è dovuto semplicemente al fatto che la frequenza con cui campioniamo il segnale, per essere ritenuta accettabile, dipende da numerosi fattori come, ad esempio, il numero di sorgenti sonore che dobbiamo analizzare (registrare correttamente la melodia prodotta da un’orchestra richiede sicuramente uno sforzo maggiore rispetto alla registrazione di un singolo strumento).
Esiste, però, una formula che ci può venire in aiuto: si tratta del Teorema di Nyquist-Shannon, che ci dice che, per non perdere informazioni utili alla ricostruzione a posteriori del segnale analogico originale, la frequenza minima di campionamento è pari al doppio della frequenza massima del segnale acquisito.
Dato che l’orecchio umano è in grado di percepire suoni fino ad un massimo di circa 20 kHz, la frequenza di campionamento delle schede audio deve essere almeno di 40 kHz (ecco il motivo per cui i CD hanno al loro interno segnali campionati a 44,1 kHz).
La quantizzazione
Dopo il campionamento, ogni elemento raccolto viene approssimato al valore numerico più vicino presente nel calcolatore.
Si dice, dunque, che il segnale è stato “quantizzato” in quanto trasformato in una quantità (un numero) da noi facilmente comprensibile ed interpretabile.
Com’è facilmente intuibile, maggiore è la quantità di numeri assegnabili dal calcolatore (ovvero la sua precisione), più simile sarà il segnale quantizzato a quello originale in termini di intensità.
Ciò però non basta: sebbene per noi questi numeri siano più che sufficienti per analizzare il segnale, al PC serve che vengano trasformati un’ultima volta.
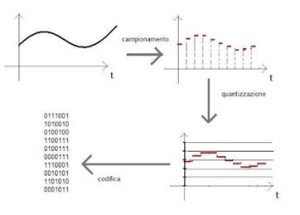
Figura 3 – Digitalizzazione e codifica del segnale
Si attua, quindi, un’operazione di codifica in cui i numeri vengono tradotti nel sistema binario, ovvero il sistema di comunicazione basilare di tutta la tecnologia digitale in cui ogni elemento è costituito da una serie di “1” e di “0”.
A questo punto, siamo finalmente riusciti a convertire un segnale analogico (come il semplice arpeggio di una chitarra) in un segnale digitale che possiamo leggere e manipolare sul nostro computer attraverso l’utilizzo di software opportuni.
Dopo aver correttamente campionato, quantizzato, codificato e realizzato una traccia audio sul nostro computer, cosa ce ne facciamo?
Il problema principale, in questi casi, è che il file così generato è estremamente pesante sia da scaricare, sia da condividere o anche più semplicemente spostare in qualsiasi zona del PC.
Per questo motivo, al giorno d’oggi nel mondo della musica digitale si fa ormai largamente uso dei Codec audio (acronimo di “Codificatore-decodificatore”): si tratta di strumenti hardware o software (principalmente software) in grado di codificare un flusso di dati al fine di poterli successivamente memorizzare e trasportare più facilmente.
L’obiettivo dei Codec è, dunque, quello di comprimere un file per renderlo più maneggevole. Tale compressione, che porta ad una riduzione della dimensione del file, ha come vantaggio il fatto di aver bisogno di un minor numero di risorse e di minore potenza di calcolo per la sua elaborazione, ma ha come svantaggio l’inevitabile perdita di alcune informazioni inizialmente contenute in esso.
Come facciamo, quindi, a sapere quali informazioni tenere e quali invece togliere?
Esistono degli specifici algoritmi di compressione che servono proprio a questo scopo e vengono usati nella realizzazione di tutti i file audio. Uno di questi è il cosiddetto approccio “time/frequency” usato nel più noto formato di file audio esistente, il formato mp3.
Utilizzando questo approccio, il file viene diviso in una serie di finestre temporali e, all’interno di ognuna di esse, vengono scartati tutti quei segnali inutili in quanto non percepiti dall’orecchio umano.
Viene dunque preso per ogni istante lo spettro del segnale acustico e vengono scartate tutte le frequenze “mascherate” da quelle adiacenti. Con il termine “effetto maschera” si intende un fenomeno fisico per il quale alcune frequenze di un segnale acustico aventi elevata ampiezza (o intensità) mascherano le frequenze adiacenti più deboli, rendendole impercettibili al nostro orecchio.
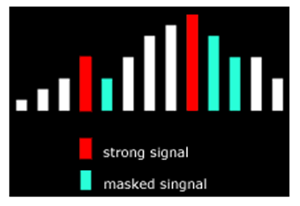
Figura 4 – Effetto maschera
Questo è solo uno dei tanti algoritmi usati per realizzare un file in formato mp3. Questo termine è infatti l’acronimo di MPEG 1 Audio Layer III, ovvero la “terza generazione” di un formato in cui al primo stadio veniva applicato soltanto il mascheramento delle frequenze per ridurre le dimensioni del file, mentre nelle generazioni successive (fino ad arrivare alla terza, che è quella tutt’ora utilizzata) vengono applicati ulteriori algoritmi di compressione dati come, ad esempio, la Codifica di Huffman.
Si chiude qui questa breve infarinatura su come avviene la realizzazione di un semplice file audio che ascoltiamo tutti i giorni con le nostre cuffiette Bluetooth, dimostrando come la fisica e la digitalizzazione siano ovunque intorno a noi… anche nella musica!
Andrea Gorreri
Foto copertina di Kevin Wuhrmann da Pixabay